
Nvidia GPU深度解析:B30A(传闻)、HGX H20、H100、B200、B300(Ultra)的全面对比
各位小伙伴们大家好哈,今天我们来聊聊Nvidia GPU!
在高性能计算和人工智能领域,Nvidia 的 GPU 一直是行业的重要推动力量。
近期,知情人士透露,NVIDIA正在为中国开发一种基于其最新Blackwell架构的新型人工智能芯片,该芯片将比目前允许在中国销售的H20型号更强大。
该新芯片暂定名为B30A,将采用单芯片(single-die)设计,性能约为B300的一半。 单芯片设计指所有主要电路都制作在同一块连续的硅晶圆上,而不是分散在多个芯片上。
新的芯片将搭载HBM高带宽内存与NVLink技术,实现处理器间的高速数据传输。
今天我们将Nvidia B30A(传闻)、HGX H20、H100、B200 和 B300(Ultra)放在一起,从架构、性能、内存技术、封装工艺以及应用场景等方面看看这些GPU有何差异。
我们将五款GPU的参数列到下面进行对比分析,以帮助读者更好地理解它们的特点和适用场景。
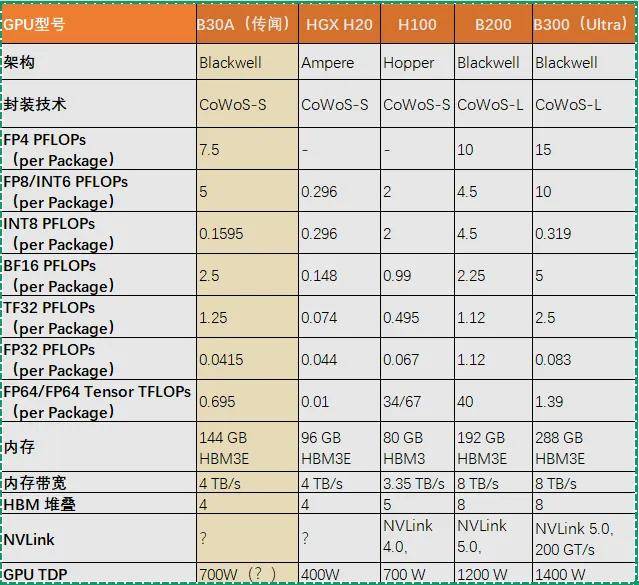
▌架构设计:从 Ampere 到 Blackwell
Nvidia 的 GPU 架构设计一直是其技术优势的核心。
HGX H20 和 H100 基于 Ampere 和 Hopper 架构,而 B30A、B200 和 B300(Ultra)则基于最新的 Blackwell 架构。
Ampere 架构以其在数据中心的广泛应用而闻名,特别是在 AI 训练和推理任务中表现出色。Hopper 架构则进一步提升了计算性能和能效,特别是在高精度计算任务中。而 Blackwell 架构则是 Nvidia 的最新力作,专为高性能计算和 AI 应用设计,提供了更高的计算能力和内存带宽。

展开全文
B30A(传闻)是基于 Blackwell Ultra 微架构的单芯片设计,旨在提供适中的性能和内存容量,同时符合特定市场的出口管制要求。
相比之下,B200 和 B300(Ultra)则采用了更复杂的多芯片设计,提供了更高的计算能力和内存容量。这种设计使得 B200 和 B300(Ultra)在处理大规模并行计算任务时表现出色,尤其是在需要高精度计算的科学计算和深度学习任务中。
▌性能表现:多精度计算能力的对比
在性能方面,这五款 GPU 的表现各有千秋。
B30A(传闻)虽然在某些精度的计算能力上不如 H100 和 B300(Ultra),但其在 FP8/INT6 和 BF16 等精度上的表现仍然令人印象深刻。这表明 B30A 在处理低精度计算任务时具有较高的效率,适合中等规模的 AI 项目。
HGX H20 在 FP8/INT6 和 BF16 等精度上的表现较为保守,但其在 FP32 高精度计算任务中表现出色。这使得 HGX H20 成为数据中心中处理科学计算和复杂 AI 模型的理想选择。
H100 作为目前 Nvidia 的旗舰 GPU,在多种精度的计算能力上都表现出色,特别是在 FP64 和 Tensor 核心的性能上。这使得 H100 成为高性能计算和 AI 应用中的首选。

B200 和 B300(Ultra)则在多精度计算能力上达到了新的高度。
B200 提供了强大的 FP4、FP8/INT6 和 BF16 计算能力,使其在处理大规模 AI 训练和推理任务时表现出色。
B300(Ultra)则进一步提升了这些性能指标,特别是在 FP4 和 FP8/INT6 等精度上,提供了极高的计算能力。这使得 B300(Ultra)成为目前市场上最强大的 GPU 之一,适用于最复杂的计算任务。
▌内存与内存带宽:性能的关键因素
内存和内存带宽是 GPU 性能的关键因素之一。
B30A(传闻)配备了 144 GB 的 HBM3E 内存和 4 TB/s 的内存带宽,这使得其在处理中等规模的 AI 项目时能够提供足够的内存容量和带宽。
HGX H20 配备了 96 GB 的 HBM3E 内存和 4 TB/s 的内存带宽,虽然在内存容量上不如 B30A,但其在高精度计算任务中表现出色。

H100 配备了 80 GB 的 HBM3 内存和 3.35 TB/s 的内存带宽,这使得其在处理高精度计算任务时能够提供足够的内存容量和带宽。
B200 和 B300(Ultra)则在内存容量和带宽上达到了新的高度。B200 配备了 192 GB 的 HBM3E 内存和 8 TB/s 的内存带宽,而 B300(Ultra)则配备了 288 GB 的 HBM3E 内存和 8 TB/s 的内存带宽。
这种设计使得 B200 和 B300(Ultra)在处理大规模并行计算任务时能够提供极高的内存容量和带宽,从而显著提升计算效率。
▌封装技术:成本与性能的平衡
封装技术是 GPU 设计中的一个重要环节,它直接影响到芯片的性能和成本。
B30A(传闻)采用了 CoWoS-S 封装技术,这种封装技术适用于单芯片设计,能够在成本和性能之间取得良好的平衡。
HGX H20 和 H100 也采用了 CoWoS-S 封装技术,这使得它们在数据中心的应用中表现出色。
B200 和 B300(Ultra)则采用了更高级的 CoWoS-L 封装技术,这种封装技术适用于多芯片设计,能够支持更大的芯片尺寸和更多的内存模块。
这种设计使得 B200 和 B300(Ultra)在处理大规模并行计算任务时能够提供更高的性能,但同时也增加了制造成本。
▌应用场景:从数据中心到高性能计算
在应用场景方面,这五款 GPU 各有其独特的优势。
B30A(传闻)主要面向中国市场,专为 AI 训练和推理任务设计。其性能和内存容量适中,适合中等规模的 AI 项目。
HGX H20 主要用于数据中心,支持大规模并行计算任务,适合 AI 训练和推理任务。
H100 作为目前 Nvidia 的旗舰 GPU,适用于高性能计算和 AI 应用,特别是在需要高精度计算的科学计算和深度学习任务中表现出色。
B200 和 B300(Ultra)则在数据中心和高性能计算领域表现出色。B200 提供了强大的计算能力和内存带宽,使其在处理大规模 AI 训练和推理任务时表现出色。
B300(Ultra)则进一步提升了这些性能指标,使其成为目前市场上最强大的 GPU 之一,适用于最复杂的计算任务。
▌总结
通过以上分析,我们可以看到,Nvidia 的 B30A(传闻)、HGX H20、H100、B200 和 B300(Ultra)在架构设计、性能表现、内存技术、封装工艺和应用场景等方面存在显著差异。
B30A(传闻)以其适中的性能和内存容量,适合中等规模的 AI 项目;HGX H20 在数据中心的应用中表现出色,特别是在高精度计算任务中;H100 作为旗舰 GPU,适用于高性能计算和 AI 应用;B200 和 B300(Ultra)则在处理大规模并行计算任务时表现出色,特别是在需要高精度计算的科学计算和深度学习任务中。
选择合适的 GPU 取决于具体的应用需求和预算。对于需要高精度计算的科学计算和深度学习任务,H100 和 B300(Ultra)是理想的选择。对于数据中心的 AI 训练和推理任务,HGX H20 和 B200 是不错的选择。而对于中等规模的 AI 项目,B30A(传闻)则是一个经济实惠的选择。
希望本文的分析能够帮助读者更好地理解这些 GPU 的特点和适用场景,从而在选择 GPU 时做出更明智的决策。





评论